背景
创建一个 deployment,一开始正常,过了一段时间,产生了几十个 Pod,状态为 Completed、Evicted
kubectl get pod NAME
READY STATUS RESTARTS AGE nginx-120-67d4669598-2kwtg 0/1 Completed 0 148m nginx-120-67d4669598-2r2hs 0/1 Completed 0 92m nginx-120-67d4669598-2rf9h 0/1 Completed 0 33m nginx-120-67d4669598-2zgn9 0/1 Evicted 0 100m nginx-120-67d4669598-4s2cl 0/1 Completed 0 100m nginx-120-67d4669598-4s688 1. 排查
我们有必要先回忆一下创建 Pod 的过程,以便我们树立排查思路。
<创建 Pod 的过程 图片>,待补充
查看 Pod
先试用 kubectl describe pod 查看 Pod 的基本信息,其中可能包含创建 Pod 的事件信息。
# kubectl describe pod nginx-120-67d4669598
Labels: app=nginx-120
pod-template-hash=67d4669598
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/nginx-120-67d4669598
Containers:
nginx:
Image: nginx:1.20
Port: <none>
Host Port: <none>
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-rfnwm (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-rfnwm:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 58s default-scheduler 0/2 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 1 node(s) had untolerated taint {node.kubernetes.io/disk-pressure: }. preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling.拿到了关键性信息,kube-scheduler 模块调度失败,原因是所有节点均存在 untolerated taint,其中1个是控制面,另一个磁盘空间不足(disk-pressure),原因找到了,节点磁盘不足。
我们先不着急解决问题,先看下背后的知识点。
2. 梳理问题背后的知识点
这里有好几个知识点
2.1 确认节点状态
使用 kubectl describe 检查节点,确实如此。
# kubectl describe node hadoop-30.com
Name: hadoop-30.com
...
Taints: node.kubernetes.io/disk-pressure:NoSchedule
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
DiskPressure True Sun, 17 Mar 2024 11:08:37 +0800 Sun, 17 Mar 2024 11:06:24 +0800 KubeletHasDiskPressure kubelet has disk pressure
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FreeDiskSpaceFailed 3m47s (x66 over 13h) kubelet (combined from similar events): Failed to garbage collect required amount of images. Attempted to free 2597299814 bytes, but only found 70534964 bytes eligible to free.翻译一下,节点正在经历磁盘空间压力,kubelet 尝试通过垃圾收集来释放空间,但未能释放足够的空间来缓解这种压力。这可能会影响该节点上运行的 Pod 的性能和稳定性,建议检查该节点上的磁盘使用情况,并采取措施释放更多空间,比如手动删除不必要的文件或调整 Pod 的资源限制,以下为详细解读:
-
Taints(污点):节点上有一个污点
node.kubernetes.io/disk-pressure:NoSchedule。这意味着因为磁盘压力问题,新的 Pod 将不会被调度到这个节点上,除非有相应的容忍度(Toleration)来忽略这个污点。 -
Conditions(条件):
- 类型:
DiskPressure(磁盘压力)。 - 状态:
True,表示节点当前确实面临磁盘空间压力。 - 最后心跳时间:
Sun, 17 Mar 2024 11:08:37 +0800,是 kubelet 最后一次报告其状态的时间。 - 最后转换时间:
Sun, 17 Mar 2024 11:06:24 +0800,是这个条件最后一次变化的时间。 - 原因:
KubeletHasDiskPressure,意味着 kubelet 报告它正在经历磁盘空间压力。 - 消息:
kubelet has disk pressure,是关于磁盘压力的简短描述。
- 类型:
-
Events(事件):
- 类型:
Warning(警告)。 - 原因:
FreeDiskSpaceFailed,表示尝试释放磁盘空间失败。 - 年龄:
3m47s (x66 over 13h),这个事件在过去 13 小时内发生了 66 次,最近一次发生在 3 分钟 47 秒前。 - 来源:
kubelet。 - 消息:
(combined from similar events): Failed to garbage collect required amount of images. Attempted to free 2597299814 bytes, but only found 70534964 bytes eligible to free.这表明 kubelet 尝试通过垃圾收集(删除不必要的镜像等)来释放 2,597,299,814 字节(约 2.42 GB)的空间,但实际上只找到了 70,534,964 字节(约 67.3 MB)的空间可以被释放,远远低于需要释放的量。
- 类型:
2.2 什么是污点(Taint)?
引用 污点和容忍度
节点亲和性 是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 (这可能出于一种偏好,也可能是硬性要求)。 污点(Taint) 则相反——它使节点能够排斥一类特定的 Pod。
我们可以主动通过 kubectl taint nodes node1 key1=value1:NoSchedule 添加污点(Taint),系统也内置一些,比如这些:
- node.kubernetes.io/not-ready:节点未准备好。这相当于节点状况 Ready 的值为 "False"。
- node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状况 Ready 的值为 "Unknown"。
- node.kubernetes.io/memory-pressure:节点存在内存压力。
- node.kubernetes.io/disk-pressure:节点存在磁盘压力。
- node.kubernetes.io/pid-pressure:节点的 PID 压力。
- node.kubernetes.io/network-unavailable:节点网络不可用。
接下来,我们了解下导致本次调度失败 disk-pressure 污点的细节。
2.3 disk-pressure 污点细节
引用 硬驱逐条件 中提到 kubelet 具有以下默认硬驱逐条件:
- memory.available<100Mi
- nodefs.available<10% 节点的根文件系统磁盘使用率低于10%
- imagefs.available<15% 镜像文件系统上的可用磁盘使用率低于15%
- nodefs.inodesFree<5%(Linux 节点)
很显然,命中了 imagefs.available<15% 这条规则。
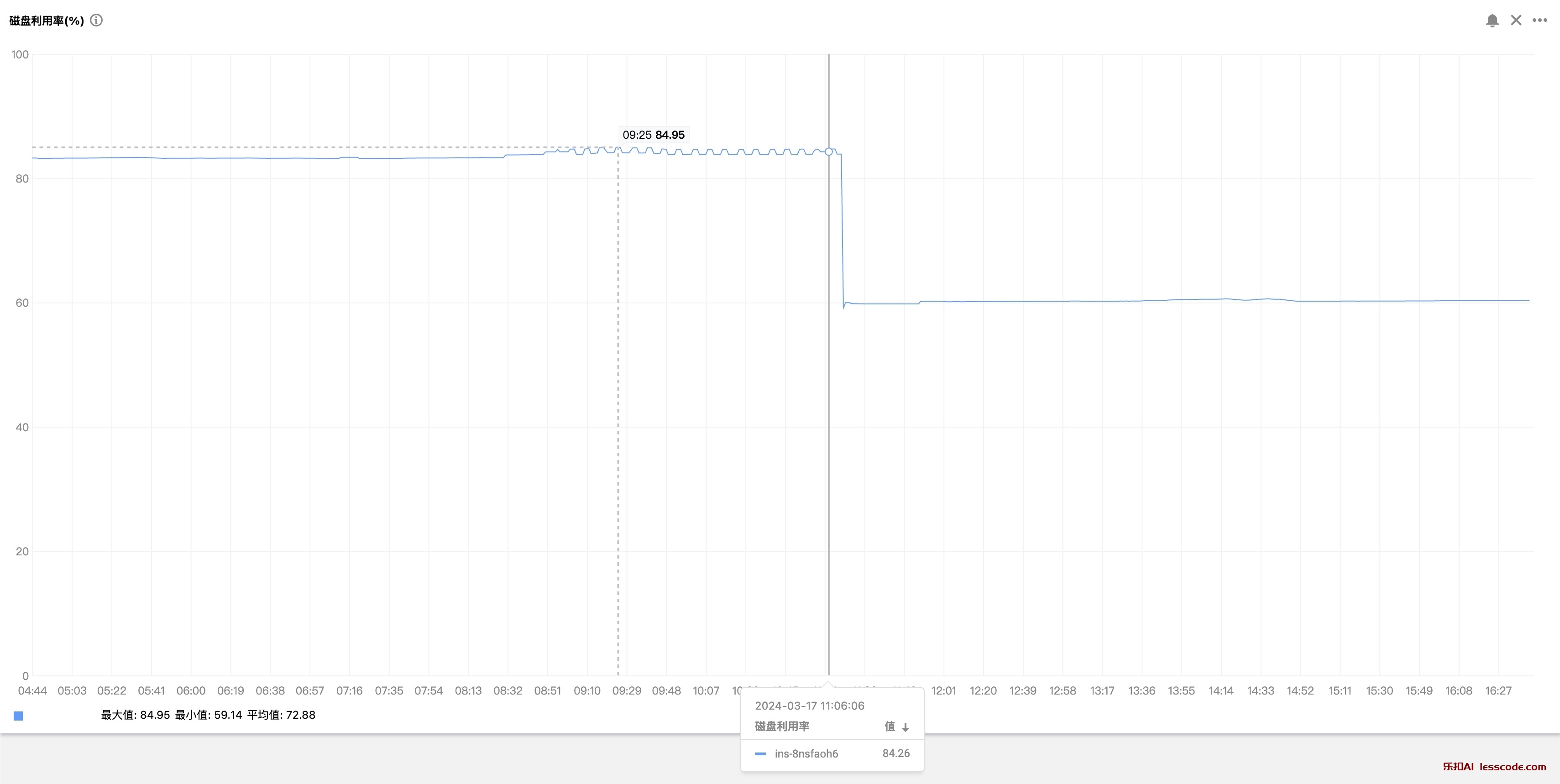
所以才会有上面提到的这句话:
- 消息:
(combined from similar events): Failed to garbage collect required amount of images. Attempted to free 2597299814 bytes, but only found 70534964 bytes eligible to free.这表明 kubelet 尝试通过垃圾收集(删除不必要的镜像等)来释放 2,597,299,814 字节(约 2.42 GB)的空间,但实际上只找到了 70,534,964 字节(约 67.3 MB)的空间可以被释放,远远低于需要释放的量。
上面这些是 kubelet 默认驱逐条件,那么是否有地方修改呢?在哪里修改呢?
2.4 kubelet 的配置文件路径
kubelet 的配置文件中可以定义驱逐条件,有几种方法查看 kubelet 的配置文件路径:
-
默认路径为
/var/lib/kubelet/config.yaml -
systemctl cat kubelet,查看守护进程配置文件
# systemctl cat kubelet
# /usr/lib/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
# /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/sysconfig/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS返回中的 Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml" 标识配置文件路径为 /var/lib/kubelet/config.yaml
- ps -ef | grep kubelet 查看启动参数
# ps -ef | grep kubelet
root 1256859 3234390 0 17:06 pts/0 00:00:00 grep --color=auto kubelet
root 3379033 1 0 3月15 ? 00:23:51 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.2.5 如何修改 kubelet 的驱逐条件
提示:本次排查问题不会修改驱逐条件,此处是为了加深理解配置
在 /var/lib/kubelet/config.yaml 可以调整驱逐条件
evictionHard:
memory.available: "500Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"然后使用 systemctl restart kubelet 重启 kubelet
2.6 确认 containerd 存储容器镜像文件系统的路径
containerd 存储容器镜像的文件系统位置可以通过查看其配置文件 /etc/containerd/config.toml 中的 root 参数来确定。
- 打开 containerd 配置文件:
vim /etc/containerd/config.toml- 查找
root参数:
# 在配置文件中搜索 "root"
/root您应该能够看到类似这样的一行:
root = "/var/lib/containerd"这个路径 /var/lib/containerd 就是 containerd 存储容器镜像和其他内容的默认位置。
- 进入该目录查看:
cd /var/lib/containerd
ls您应该能看到类似以下内容:
btrfs
io.containerd.content.v1.content
io.containerd.metadata.v1.bucket
io.containerd.runtime.v1.linux
io.containerd.runtime.v2.task
metadata.db其中:
io.containerd.content.v1.content目录存储着拉取下来的镜像层文件io.containerd.metadata.v1.bucket目录存储着镜像元数据
所以,containerd 默认将容器镜像存储在 /var/lib/containerd 目录下。如果您修改过配置文件中的 root 参数,则对应的就是您设置的路径。
接下来我们需要清理 /var/lib/container 所在分区的空间。
3. 解决问题
df -h确认确实磁盘可用率低于 15%- 使用
du -sh *排查 - 处理不需要的问题
问题解决。
确认一下节点状态,DiskPressure 状态为 False,即正常了,没有遇到磁盘压力。
# kubectl describe node hadoop-30.com
Name: hadoop-30.com
CreationTimestamp: Fri, 15 Mar 2024 22:19:01 +0800
Taints: <none>
Unschedulable: false
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Fri, 15 Mar 2024 22:50:38 +0800 Fri, 15 Mar 2024 22:50:38 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure False Sun, 17 Mar 2024 21:30:49 +0800 Fri, 15 Mar 2024 22:19:01 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sun, 17 Mar 2024 21:30:49 +0800 Sun, 17 Mar 2024 11:13:23 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Sun, 17 Mar 2024 21:30:49 +0800 Fri, 15 Mar 2024 22:19:01 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Sun, 17 Mar 2024 21:30:49 +0800 Sun, 17 Mar 2024 19:30:23 +0800 KubeletReady kubelet is posting ready status
...
Events: <none>Pod 也正常了。
好的,本次 troubleshooting 到此结束。