安装 KubeSphere v3.4.0,优秀的K8S容器管理平台
介绍
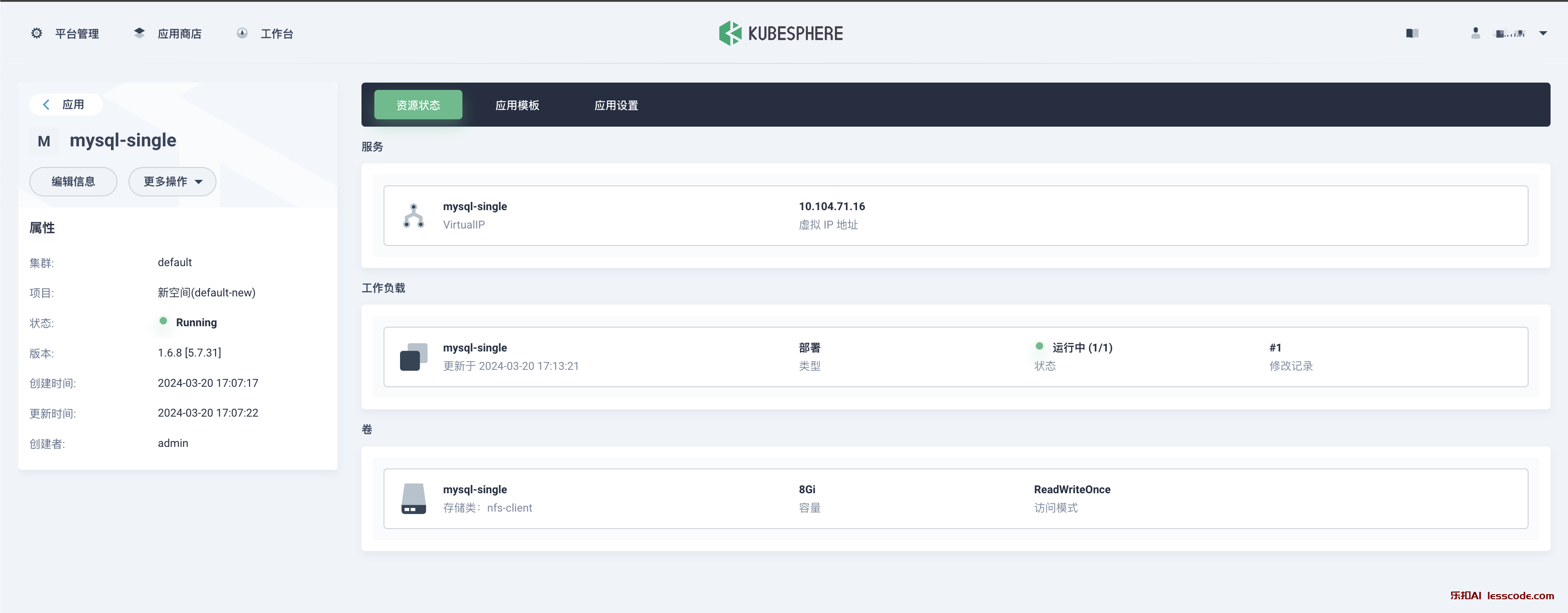
kubesphere,适用于 Kubernetes 多云、数据中心和边缘 管理的容器平台.
KubeSphere 愿景是打造一个以 Kubernetes 为内核的 云原生分布式操作系统,它的架构可以非常方便地使第三方应用与云原生生态组件进行即插即用(plug-and-play)的集成,支持云原生应用在多云与多集群的统一分发和运维管理,下图为产品架构图。
安装
前置项
- 准备好默认的 StorageClass
现有 Kubernetes 集群(v1.29.2)上安装 KubeSphere
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.4.0/cluster-configuration.yaml查看安装过程
kubectl logs ks-installer-6bdfffb7d-9kb2j -n kubesphere-system -f安装成功,使用 节点的IP:30880 登录 KubeSphere 控制台,默认账号 admin/P@88w0rd
# kubectl get svc ks-console -n kubesphere-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ks-console NodePort 10.111.251.177 <none> 80:30880/TCP 34h-
集群管理首页

-
集群状态
-
节点状态
问题



登录
遇到问题
request to http://ks-apiserver/oauth/token failed, reason: getaddrinfo EAI_AGAIN ks-apiserver排查,控制台登录的 ks-console Pod 请求 ks-apiserver Pod 失败,初步判定是负责集群内 DNS 解析的 coredns 引起的
# kubectl logs ks-console-56b9b686c8-k8nxq -n kubesphere-system -f
> kubesphere-console@3.0.0 serve /opt/kubesphere/console
> NODE_ENV=production node server/server.js
Dashboard app running at port 8000
--> POST /login 200 5,004ms 120b 2024/03/19T12:59:04.570
<-- POST /login 2024/03/19T13:07:00.295
FetchError: request to http://ks-apiserver/oauth/token failed, reason: getaddrinfo EAI_AGAIN ks-apiserver
at ClientRequest.<anonymous> (/opt/kubesphere/console/server/server.js:19500:11)
at ClientRequest.emit (events.js:314:20)
at Socket.socketErrorListener (_http_client.js:427:9)
at Socket.emit (events.js:314:20)
at emitErrorNT (internal/streams/destroy.js:92:8)
at emitErrorAndCloseNT (internal/streams/destroy.js:60:3)
at processTicksAndRejections (internal/process/task_queues.js:84:21) {
type: 'system',
errno: 'EAI_AGAIN',
code: 'EAI_AGAIN'
}根据官方社区 KubeSphere v3.1安装成功后,登录失败 的指引,注释 coredns 的向上解析配置 forward。
# kubectl -n kube-system edit cm coredns -o yaml
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
#forward . /etc/resolv.conf {
# max_concurrent 1000
# }
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2024-03-15T06:21:58Z"
name: coredns
namespace: kube-system
resourceVersion: "500334"
uid: 3dadaea2-3800-4ae6-95d0-8c75713b3c1f思考:forward 本来用于集群外部域名,注释后,后续会出现无法解析外部域名的情况,查看文末。
重启 Pod
# kubectl rollout restart deploy coredns -n kube-system
deployment.apps/coredns restarted登录正常。
pod prometheus-k8s-0 初始化失败
# kubectl describe pod/prometheus-k8s-0 -n kubesphere-monitoring-system
Name: prometheus-k8s-0
Namespace: kubesphere-monitoring-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 27s default-scheduler Successfully assigned kubesphere-monitoring-system/prometheus-k8s-0 to hadoop-30.com
Warning FailedMount 11s (x6 over 26s) kubelet MountVolume.SetUp failed for volume "secret-kube-etcd-client-certs" : secret "kube-etcd-client-certs" not found确实找不到 secret kube-etcd-client-certs
# kubectl get secrets -n kubesphere-monitoring-system
NAME TYPE DATA AGE
alertmanager-main Opaque 1 5h52m
alertmanager-main-generated Opaque 1 5h52m
alertmanager-main-tls-assets-0 Opaque 0 5h52m
notification-manager-webhook-server-cert kubernetes.io/tls 2 5h51m
prometheus-k8s Opaque 1 5h52m
prometheus-k8s-tls-assets-0 Opaque 0 5h52m
prometheus-k8s-web-config Opaque 1 5h52m
sh.helm.release.v1.notification-manager.v1 helm.sh/release.v1 1 5h51m
sh.helm.release.v1.notification-manager.v2 helm.sh/release.v1 1 5h51m根据 KubeSphere 社区 指引,创建之。
kubectl -n kubesphere-monitoring-system create secret generic kube-etcd-client-certs \
--from-file=etcd-client-ca.crt=/etc/kubernetes/pki/etcd/ca.crt \
--from-file=etcd-client.crt=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
--from-file=etcd-client.key=/etc/kubernetes/pki/etcd/healthcheck-client.key重启
# kubectl rollout restart statefulset prometheus-k8s -n kubesphere-monitoring-system
Warning: spec.template.spec.containers[1].ports[0]: duplicate port definition with spec.template.spec.initContainers[0].ports[0]
statefulset.apps/prometheus-k8s restarted运行正常了, kubesphere 的监控图表也出来了。
# kubectl get pod prometheus-k8s-0 -n kubesphere-monitoring-system
NAME READY STATUS RESTARTS AGE
prometheus-k8s-0 2/2 Running 0 15m开启组件过多,导致服务器高负载
只有一个工作节点,已经 NodeNotReady 了
# kubectl describe node hadoop-30.com
Container Runtime Version: containerd://1.7.14
Kubelet Version: v1.29.2
Kube-Proxy Version: v1.29.2
PodCIDR: 10.244.1.0/24
PodCIDRs: 10.244.1.0/24
Non-terminated Pods: (38 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nfs-client-provisioner-648798c484-ljrc6 0 (0%) 0 (0%) 0 (0%) 0 (0%) 162m
default nginx-1-17-5d5dc64fc7-7b6hl 0 (0%) 0 (0%) 0 (0%) 0 (0%) 40h
default nginx-59dc9c9459-nf9cb 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d1h
default nginx-web-65d5f4d459-ptt46 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28h
default redis-7c888f4788-gflms 0 (0%) 0 (0%) 0 (0%) 0 (0%) 42h
kube-flannel kube-flannel-ds-mp2hz 100m (2%) 0 (0%) 50Mi (0%) 0 (0%) 3d14h
kube-system coredns-856fc85d8f-7cjl4 100m (2%) 0 (0%) 70Mi (0%) 170Mi (2%) 23m
kube-system coredns-856fc85d8f-f7wnd 100m (2%) 0 (0%) 70Mi (0%) 170Mi (2%) 23m
kube-system kube-proxy-j2dmm 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3d15h
kube-system metrics-server-95d9bdd76-gmbhs 0 (0%) 0 (0%) 0 (0%) 0 (0%) 12m
kube-system snapshot-controller-0 0 (0%) 0 (0%) 0 (0%) 0 (0%) 155m
kubernetes-dashboard kubernetes-dashboard-api-6c49db8b5d-kxxdg 100m (2%) 250m (6%) 200Mi (2%) 400Mi (5%) 16h
kubernetes-dashboard kubernetes-dashboard-api-6c49db8b5d-pm66j 100m (2%) 250m (6%) 200Mi (2%) 400Mi (5%) 16h
kubernetes-dashboard kubernetes-dashboard-api-6c49db8b5d-w7l2n 100m (2%) 250m (6%) 200Mi (2%) 400Mi (5%) 16h
kubernetes-dashboard kubernetes-dashboard-auth-77fc776d6f-5q54s 100m (2%) 250m (6%) 200Mi (2%) 400Mi (5%) 16h
kubernetes-dashboard kubernetes-dashboard-kong-cbdf8f7d9-bndnn 0 (0%) 0 (0%) 0 (0%) 0 (0%) 16h
kubernetes-dashboard kubernetes-dashboard-metrics-scraper-956d55d9-46dj2 100m (2%) 250m (6%) 200Mi (2%) 400Mi (5%) 16h
kubernetes-dashboard kubernetes-dashboard-web-5f57f6bc56-v5cxv 100m (2%) 250m (6%) 200Mi (2%) 400Mi (5%) 16h
kubesphere-controls-system default-http-backend-68686bdb6-bbxxt 10m (0%) 10m (0%) 20Mi (0%) 20Mi (0%) 154m
kubesphere-controls-system kubectl-admin-7df4b6b5b6-xwmr5 0 (0%) 0 (0%) 0 (0%) 0 (0%) 147m
kubesphere-logging-system fluent-bit-zxqbs 10m (0%) 500m (12%) 25Mi (0%) 200Mi (2%) 9m59s
kubesphere-logging-system fluentbit-operator-687c567566-sncr7 10m (0%) 200m (5%) 20Mi (0%) 200Mi (2%) 10m
kubesphere-logging-system logsidecar-injector-deploy-56f59bcbcf-9qzs7 20m (0%) 200m (5%) 20Mi (0%) 200Mi (2%) 7m24s
kubesphere-logging-system logsidecar-injector-deploy-56f59bcbcf-gck6w 20m (0%) 200m (5%) 20Mi (0%) 200Mi (2%) 7m24s
kubesphere-logging-system opensearch-cluster-data-0 1 (25%) 0 (0%) 1536Mi (19%) 0 (0%) 10m
kubesphere-logging-system opensearch-cluster-master-0 1 (25%) 0 (0%) 512Mi (6%) 0 (0%) 10m
kubesphere-monitoring-system alertmanager-main-0 120m (3%) 300m (7%) 80Mi (1%) 250Mi (3%) 150m
kubesphere-monitoring-system kube-state-metrics-65c69d6b64-l7s77 120m (3%) 3 (75%) 190Mi (2%) 8392Mi (108%) 151m
kubesphere-monitoring-system node-exporter-84k4s 112m (2%) 2 (50%) 200Mi (2%) 600Mi (7%) 151m
kubesphere-monitoring-system notification-manager-deployment-85757c9bfb-hn78m 5m (0%) 500m (12%) 20Mi (0%) 500Mi (6%) 149m
kubesphere-monitoring-system notification-manager-operator-859d858c57-dgvgq 10m (0%) 100m (2%) 30Mi (0%) 100Mi (1%) 149m
kubesphere-monitoring-system prometheus-operator-77d99c696f-qrgws 110m (2%) 1200m (30%) 120Mi (1%) 300Mi (3%) 151m
kubesphere-system ks-apiserver-85cdc5f879-44gsb 20m (0%) 1 (25%) 100Mi (1%) 1Gi (13%) 154m
kubesphere-system ks-console-56b9b686c8-k8nxq 20m (0%) 1 (25%) 100Mi (1%) 1Gi (13%) 154m
kubesphere-system ks-controller-manager-5df5cd69f-n5drp 30m (0%) 1 (25%) 50Mi (0%) 1000Mi (12%) 154m
kubesphere-system ks-installer-6bdfffb7d-bz5t7 20m (0%) 1 (25%) 100Mi (1%) 1Gi (13%) 156m
kubesphere-system minio-6476d94fcb-4dw8z 250m (6%) 0 (0%) 256Mi (3%) 0 (0%) 11m
kubesphere-system openpitrix-import-job-jdfnv 0 (0%) 0 (0%) 0 (0%) 0 (0%) 8m2s
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 3787m (94%) 13710m (342%)
memory 4789Mi (62%) 17774Mi (230%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeNotReady 4m22s node-controller Node hadoop-30.com status is now: NodeNotReady控制台已经进去不了,通过在控制面的节点上修改自定义资源配置 ClusterConfiguration。
[root@clouderamanager-15 net.d]# kubectl get crd | grep clusterconfiguration
clusterconfigurations.installer.kubesphere.io 2024-03-19T01:44:21Z
[root@clouderamanager-15 net.d]# kubectl get clusterconfigurations.installer.kubesphere.io -A
NAMESPACE NAME AGE
kubesphere-system ks-installer 3h56m将部分组件从 true 改成 false
[root@clouderamanager-15 net.d]# kubectl edit clusterconfiguration ks-installer -n kubesphere-system
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: installer.kubesphere.io/v1alpha1
kind: ClusterConfiguration
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
creationTimestamp: "2024-03-19T01:44:59Z"
generation: 12
labels:
version: v3.4.0
name: ks-installer
namespace: kubesphere-system
resourceVersion: "504258"
uid: 86e53ba6-7a78-4175-b1ae-34afc18ff7b8
spec:
alerting:
enabled: true
auditing:
enabled: false
authentication:
jwtSecret: ""
common:
core:
console:
enableMultiLogin: true
port: 30880
type: NodePort
es:
basicAuth:
enabled: false
password: ""
username: ""
elkPrefix: logstash
enabled: false
externalElasticsearchHost: ""
externalElasticsearchPort: ""
logMaxAge: 7
gpu:
kinds:
- default: true
resourceName: nvidia.com/gpu
resourceType: GPU
minio:
volumeSize: 20Gi
monitoring:
GPUMonitoring:
enabled: false
endpoint: http://prometheus-operated.kubesphere-monitoring-system.svc:9090
openldap:
enabled: false
volumeSize: 2Gi
opensearch:
basicAuth:
enabled: true
password: admin
username: admin
dashboard:
enabled: false
enabled: true
externalOpensearchHost: ""
externalOpensearchPort: ""
logMaxAge: 7
opensearchPrefix: whizard
redis:
enableHA: false
/logg
enabled: false
kubeedge:
cloudCore:
cloudHub:
advertiseAddress:
- ""
service:
cloudhubHttpsNodePort: "30002"
cloudhubNodePort: "30000"
cloudhubQuicNodePort: "30001"
cloudstreamNodePort: "30003"
tunnelNodePort: "30004"
enabled: false
iptables-manager:
enabled: true
mode: external
etcd:
endpointIps: localhost
monitoring: true
port: 2379
tlsEnable: true
events:
enabled: false
ruler:
enabled: true
replicas: 2
gatekeeper:
enabled: false
local_registry: ""
logging:
enabled: false
logsidecar:
enabled: true
replicas: 2
metrics_server:
enabled: true
monitoring:
gpu:
nvidia_dcgm_exporter:
enabled: false
node_exporter:
port: 9100
storageClass: ""
multicluster:
clusterRole: none
network:
ippool:
type: none
networkpolicy:
enabled: false
topology:
type: none
openpitrix:
store:
enabled: false
persistence:
storageClass: ""
servicemesh:
enabled: false
"/tmp/kubectl-edit-3078338335.yaml" 166L, 6067C written
clusterconfiguration.installer.kubesphere.io/ks-installer edited恢复正常了。
[root@clouderamanager-15 net.d]# kubectl describe node hadoop-30.com
Name: hadoop-30.com
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=hadoop-30.com
kubernetes.io/os=linux
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"66:be:4f:9f:61:7e"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 10.0.0.30
kubeadm.alpha.kubernetes.io/cri-socket: unix:///var/run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 15 Mar 2024 22:19:01 +0800
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: hadoop-30.com
AcquireTime: <unset>
RenewTime: Tue, 19 Mar 2024 13:45:02 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Tue, 19 Mar 2024 13:42:10 +0800 Tue, 19 Mar 2024 13:42:10 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure False Tue, 19 Mar 2024 13:41:18 +0800 Tue, 19 Mar 2024 13:41:18 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Tue, 19 Mar 2024 13:41:18 +0800 Tue, 19 Mar 2024 13:41:18 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Tue, 19 Mar 2024 13:41:18 +0800 Tue, 19 Mar 2024 13:41:18 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Tue, 19 Mar 2024 13:41:18 +0800 Tue, 19 Mar 2024 13:41:18 +0800 KubeletReady kubelet is posting ready status
...
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 3637m (90%) 17810m (445%)
memory 4843Mi (62%) 33868Mi (438%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 3m38s kube-proxy
Normal NodeNotReady 10m node-controller Node hadoop-30.com status is now: NodeNotReady
Normal Starting 3m45s kubelet Starting kubelet.
Warning InvalidDiskCapacity 3m45s kubelet invalid capacity 0 on image filesystem
Normal NodeAllocatableEnforced 3m45s kubelet Updated Node Allocatable limit across pods
Warning Rebooted 3m45s (x2 over 3m45s) kubelet Node hadoop-30.com has been rebooted, boot id: 04507eb1-eedc-43f9-b2c0-a9c373d30a65
Normal NodeHasSufficientMemory 3m45s (x3 over 3m45s) kubelet Node hadoop-30.com status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 3m45s (x3 over 3m45s) kubelet Node hadoop-30.com status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 3m45s (x3 over 3m45s) kubelet Node hadoop-30.com status is now: NodeHasSufficientPID
Normal NodeNotReady 3m45s (x2 over 3m45s) kubelet Node hadoop-30.com status is now: NodeNotReady
Normal NodeReady 3m45s kubelet Node hadoop-30.com status is now: NodeReady应用商店
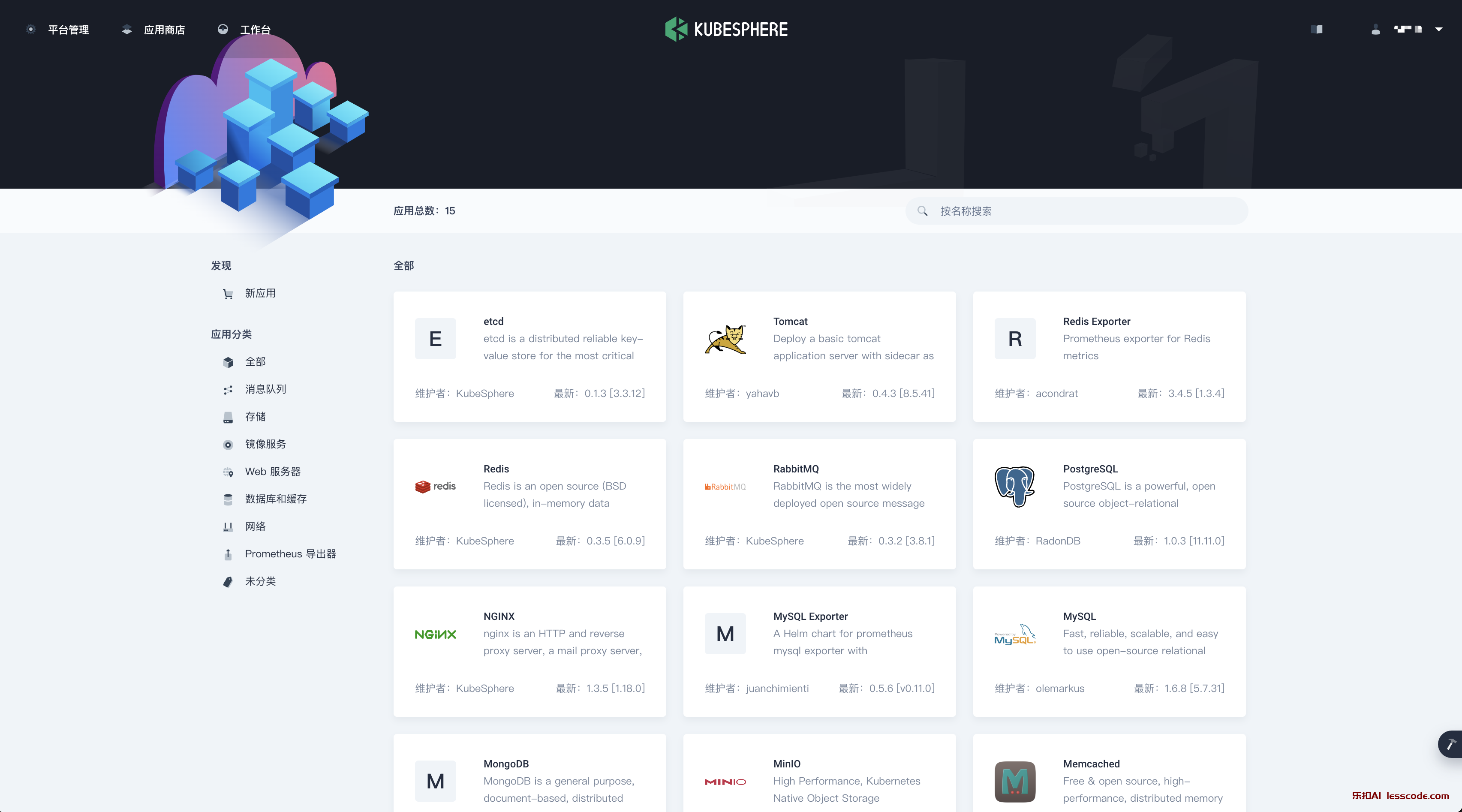
集群配置中 开启 应用商店
kubesphere 通过 CRD clusterconfiguration 来管理集群的配置,比如安装 kubesphere 或 添加组件(应用商店 openpitrix)
kubectl edit clusterconfiguration ks-installer -n kubesphere-system将 openpitrix.store.enabled 的值设置为 true
openpitrix:
store:
enabled: true查看安装过程
kubectl logs ks-installer-6bdfffb7d-9kb2j -n kubesphere-system -f安装成功后,顶部导航增加了应用商店入口。
默认只有15个应用,如果需要更多的营养,可以添加应用仓库。
创建企业空间、项目
为了添加应用仓库,需要先创建企业空间,默认的企业空间 system-workspace(system-workspace is a built-in workspace automatically created by KubeSphere. It contains all system components to run KubeSphere) 主要用于 KubeSphere 组件的部署。
参照官方文档 创建企业空间、项目、用户和平台角色 即可。
添加 Helm 仓库
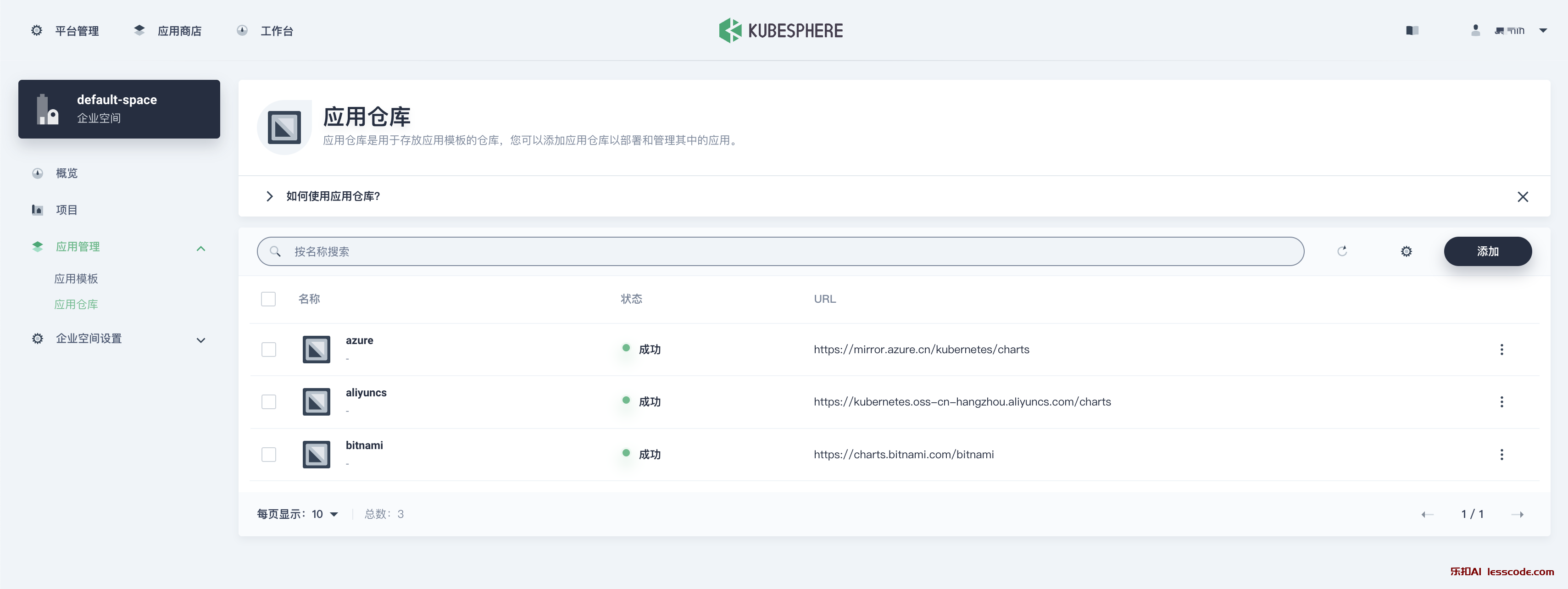
从 工作台 进入刚创建的空间,应用管理下找到应用仓库,右侧添加。
以下是3个丰富的 Helm 仓库
https://charts.bitnami.com/bitnami
https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
https://mirror.azure.cn/kubernetes/charts添加过程中可能遇到报错
Bad Request Get “https://charts.bitnami.com/bitnami/index.yaml”: dial tcp: lookup charts.bitnami.com on 10.96.0.10:53: server misbehaving的配置。, 原因是 Pod 请求仓库时会向 coredns 发起域名解析,而 CoreDNS 在前面我们遇到登录问题时注释了引用节点上/etc/resolv.conf解决办法:使用
kubectl edit cm coredns -n kube-system取消注释即可,发现现在不影响登录了。
创建应用
进入新的空间 -> 应用负载 -> 应用 -> 创建应用(从应用模版)