CDH 6.3.1 部署 Kylin 3.0.1
1. Kylin 是什么?
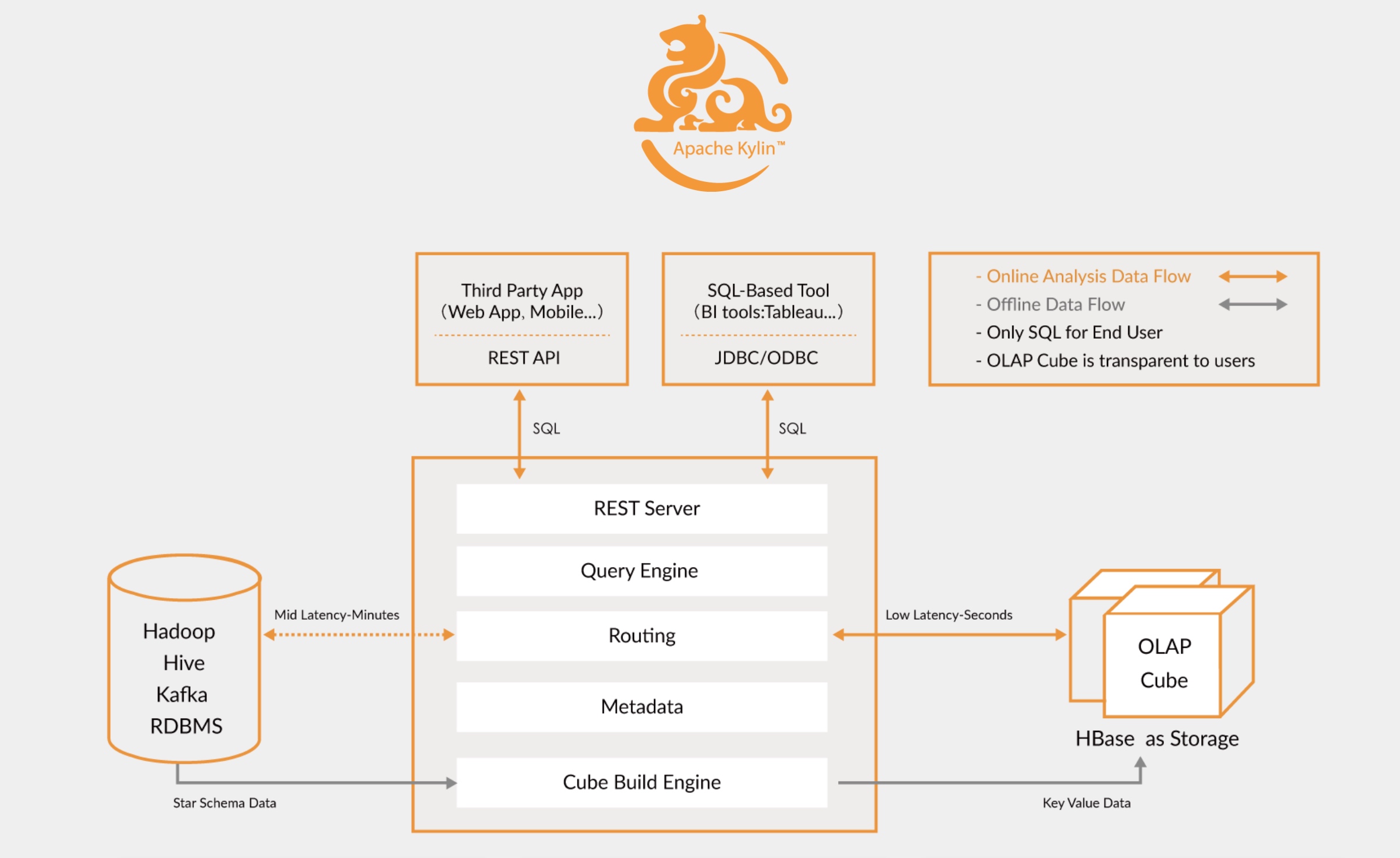
一种数据仓库,通过建模,进行预计算(Mapreduce、Spark 等),实现交互式查询大规模数据。
Apache Kylin™ 是一个开源的、分布式的分析型数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
2. 安装 Kylin 3.0.1
由于 Cloudera Manager 6.3 无法直接部署 Kylin, 所以需要按照 官方文档open in new window 进行安装。
2.1 环境准备
CDH 中 HDFS、Yarn、Hive、HBase 需要在运行中。
- Hadoop: 2.7+, 3.1+ (since v2.5) // CDH 6.3.1 的版本是 3.0open in new window,背后其实是 HDFS、Yarn 等。
- Hive: 0.13 - 1.2.1+ // CDH 6.3.1 的 Hive 版本是 2.1.1
- HBase: 1.1+, 2.0 (since v2.5) // CDH 6.3.1 的 Hive 版本是 2.1.4
Spark (可选) 2.3.0+ // 不用运行,可使用安装脚本中的版本 Kafka (可选) 1.0.0+ (since v2.5) // 作为构建 cube 的渠道,非默认,可不用 JDK: 1.8+ (since v2.5) OS: Linux only, CentOS 6.5+ or Ubuntu 16.0.4+ // 本次部署是 CentOS 7.6
2.2 下载版本
从 Apache Kylin 下载网站open in new window 下载一个适用于您 Hadoop 版本的二进制文件。
本文下载了 2020-02-20 发布的 v3.0.1。
# cd /usr/local/
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/kylin/apache-kylin-3.0.1/apache-kylin-3.0.1-bin-cdh60.tar.gz
# tar zxf apache-kylin-3.0.1-bin-cdh60.tar.gz
# cd apache-kylin-3.0.1-bin-cdh60
# export KYLIN_HOME=`pwd`
# $KYLIN_HOME/bin/download-spark.sh ## 默认会存放在 spark/ 目录下
2
3
4
5
6
2.3 设置运行环境
- 修改
~/.bash_profile,并source ~/.bash_profile
export HADOOP_USER_NAME=hdfs
export KYLIN_HOME=/data/cloudrea_manager/work_directory/apache-kylin-3.0.1-bin-cdh60
2
- 拷贝
commons-configuration-1.6.jar到$KYLIN_HOME/lib下
不做此时,将导致 Kylin Web 404 可以提前用
locate搜索一下路径
# cp /opt/cloudera/parcels/KAFKA-4.1.0-1.4.1.0.p0.4/lib/kafka/libs/commons-configuration-1.6.jar lib/
- 修改
hbase脚本
在 /opt/cloudera/parcels/CDH/lib/hbase/bin/hbase 的 CLASSPATH 变量中追加 /opt/cloudera/parcels/CDH/lib/hbase/lib/*
以下为示例
CLASSPATH="${HBASE_CONF_DIR}"
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/opt/cloudera/parcels/CDH/lib/hbase/lib/*
2
- 检查运行环境
$KYLIN_HOME/bin/check-env.sh
2.4 安装 Kylin
其实就是启动。
$KYLIN_HOME/bin/kylin.sh start
Kylin 启动后您可以通过浏览器 http://<hostname>:7070/kylin 进行访问。
初始用户名和密码是 ADMIN/KYLIN (大写啊)
3. 样例 Cube 快速入门
3.1 初始化 Cube
${KYLIN_HOME}/bin/sample.sh
3.2 Build Cubes
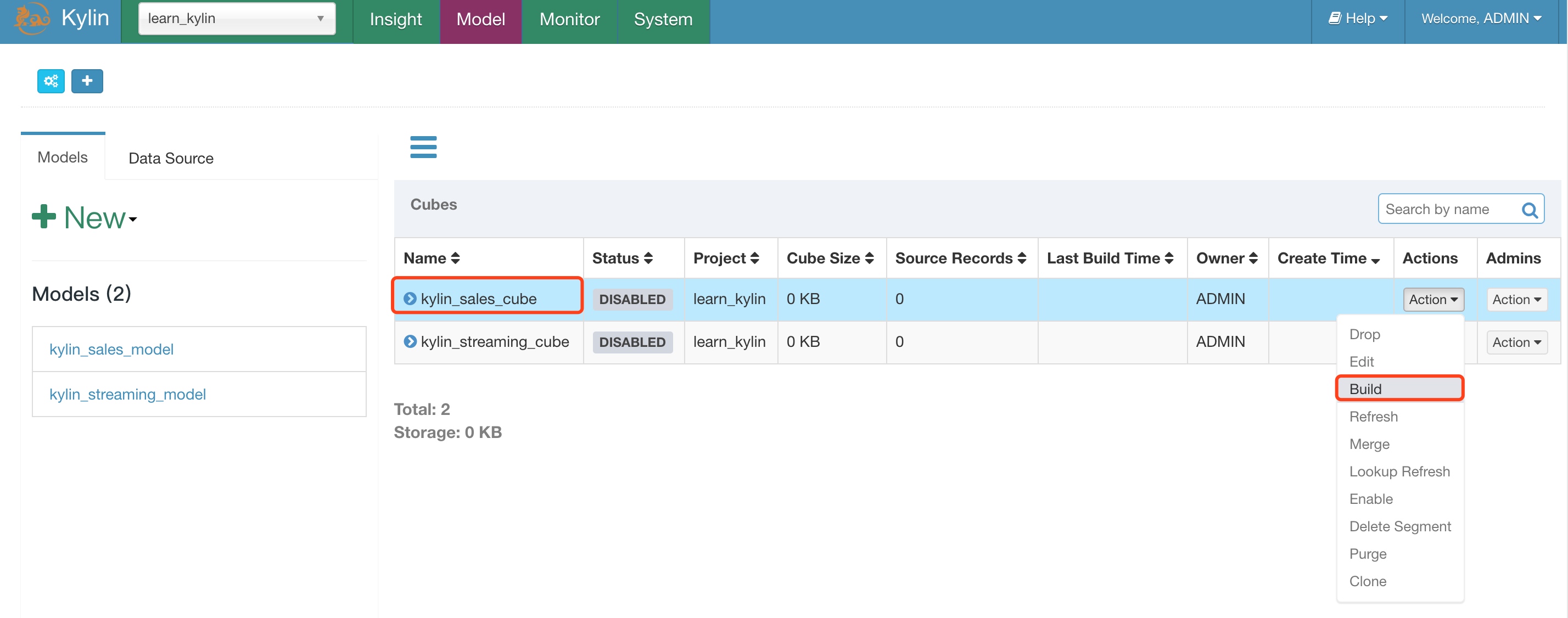
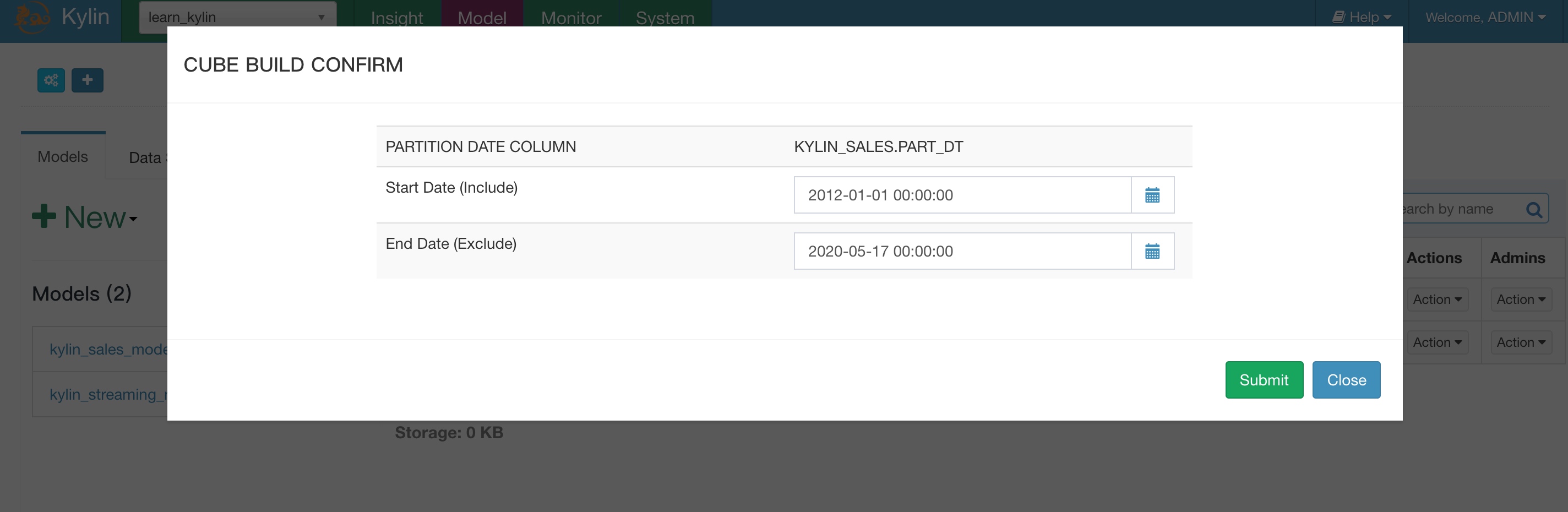
选择时间,截止时间选择今天即可。
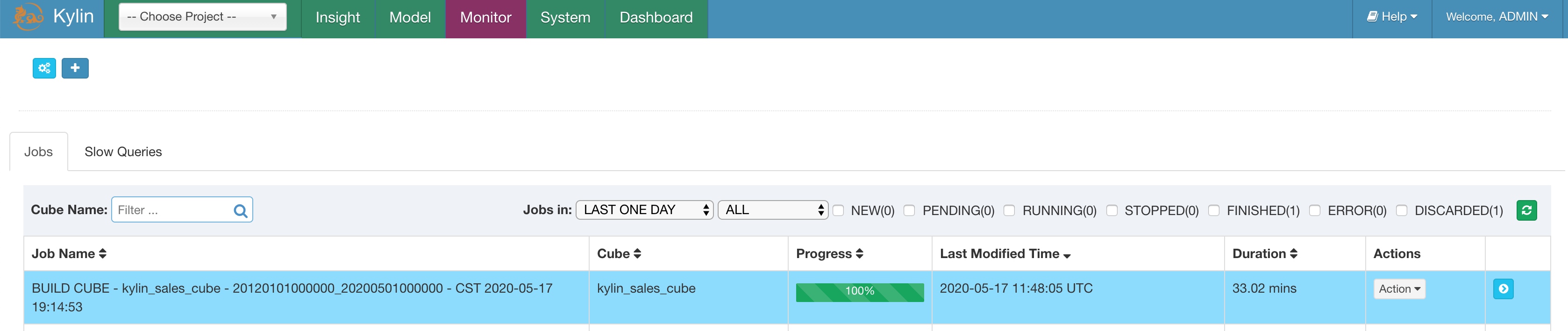
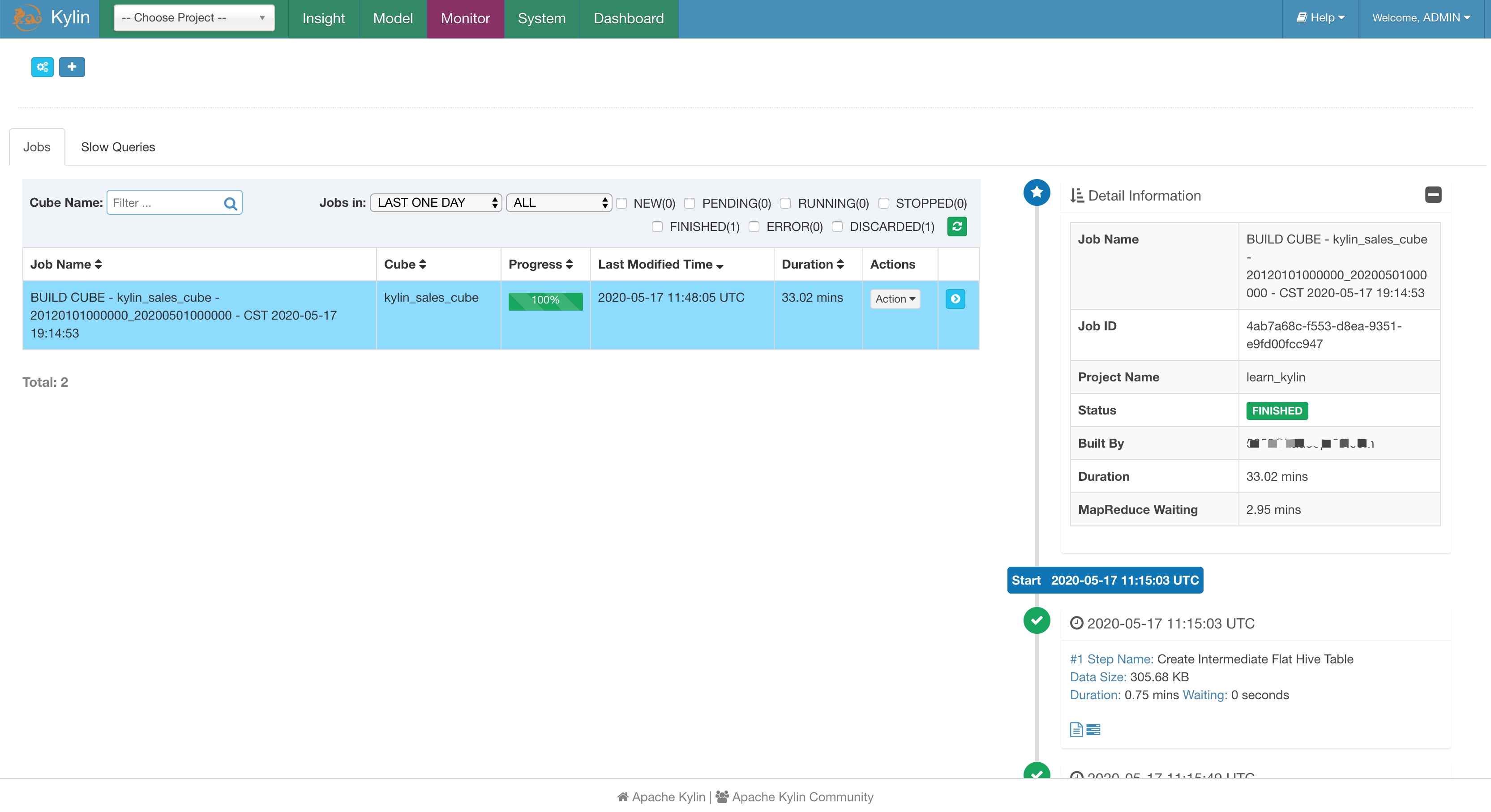
其实背后是 Mapreduce 任务 
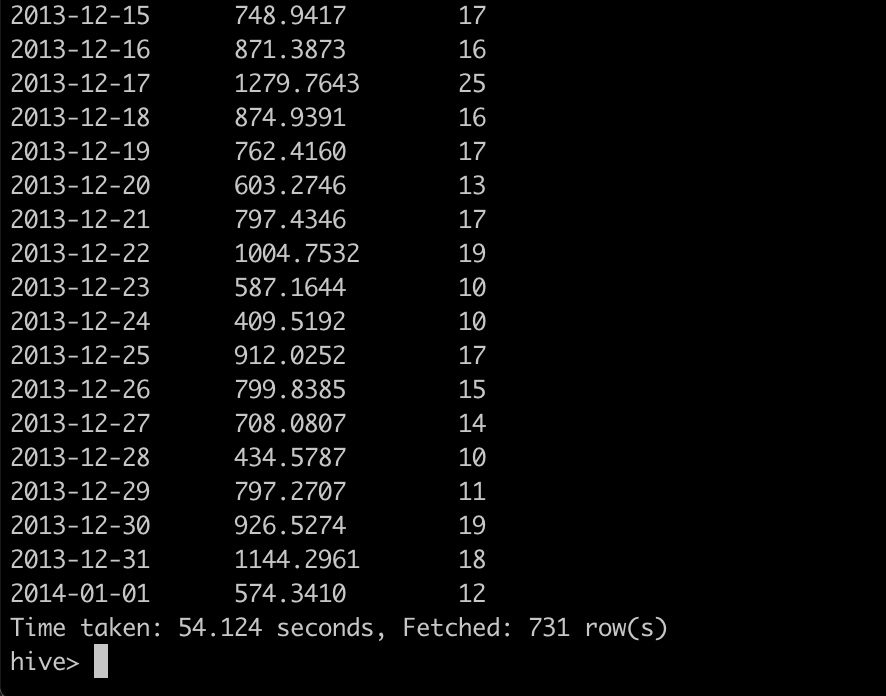
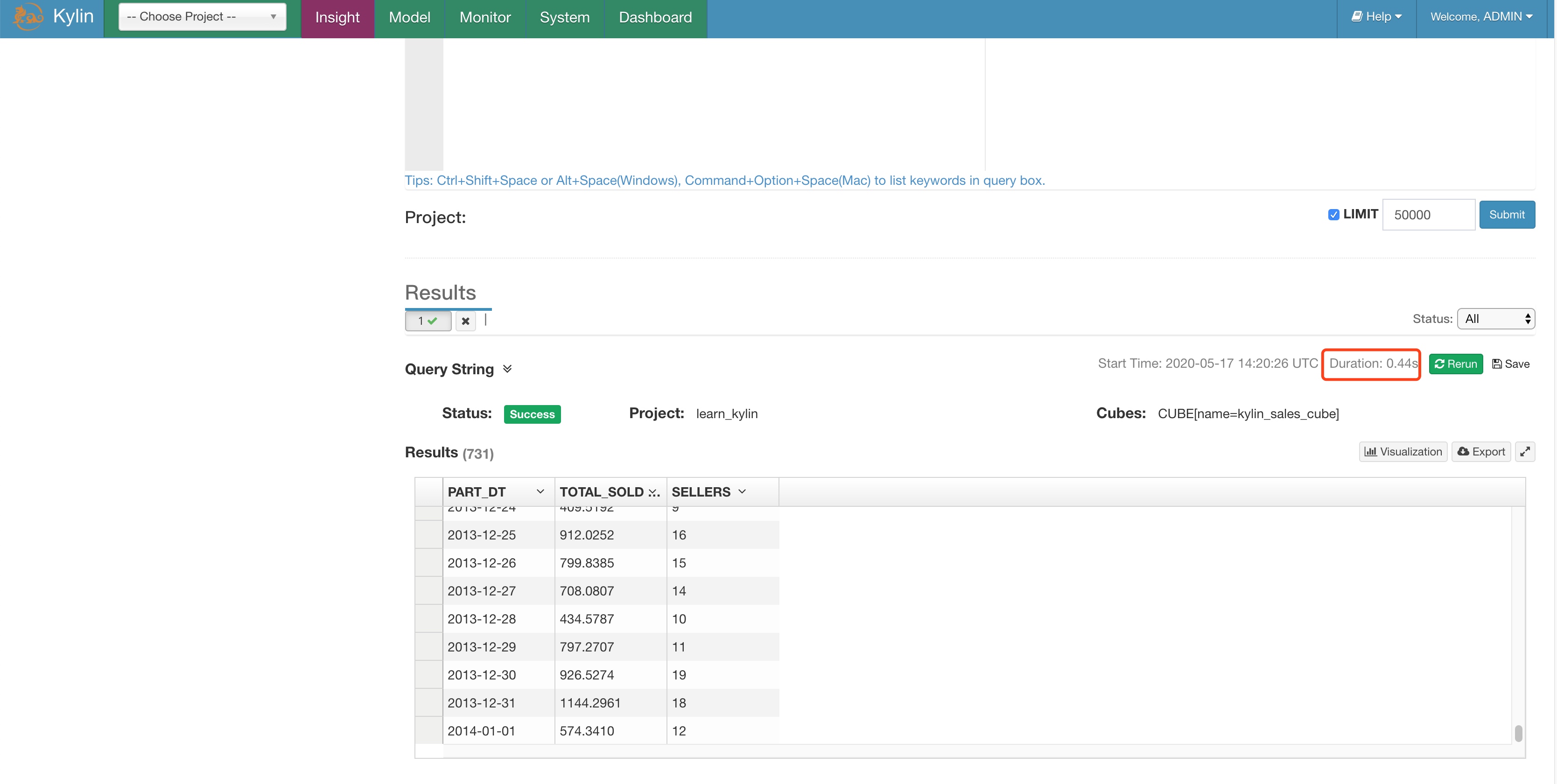
3.3 对比下查询效果
select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
hive 下 54.124 秒
Kylin 中 0.4 秒
常见报错
Kylin 打不开 Web UI,提示 404
- 拷贝
commons-configuration-1.6.jar到$KYLIN_HOME/lib下
不做此时,将导致 Kylin Web 404 可以提前用
locate搜索一下路径
# cp /opt/cloudera/parcels/KAFKA-4.1.0-1.4.1.0.p0.4/lib/kafka/libs/commons-configuration-1.6.jar lib/
2020-05-17 12:48:54,302 ERROR [localhost-startStop-1] context.ContextLoader:350 : Context initialization failed
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping': Invocation of init method failed; nested exception is java.lang.NoClassDefFoundError: org/apache/commons/configuration/ConfigurationException
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1628)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:555)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:483)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:306)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:302)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:761)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:867)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:543)
at org.springframework.web.context.ContextLoader.configureAndRefreshWebApplicationContext(ContextLoader.java:443)
at org.springframework.web.context.ContextLoader.initWebApplicationContext(ContextLoader.java:325)
at org.springframework.web.context.ContextLoaderListener.contextInitialized(ContextLoaderListener.java:107)
at org.apache.catalina.core.StandardContext.listenerStart(StandardContext.java:4792)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5256)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:150)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:754)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:730)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:734)
at org.apache.catalina.startup.HostConfig.deployWAR(HostConfig.java:985)
at org.apache.catalina.startup.HostConfig$DeployWar.run(HostConfig.java:1857)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoClassDefFoundError: org/apache/commons/configuration/ConfigurationException
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
dfs 没权限,因为启动没设置 export HADOOP_USER_NAME=hdfs
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=root, access=WRITE, inode="/kylin":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1855)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1839)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1798)
at org.apache.hadoop.hdfs.server.namenode.FSDirMkdirOp.mkdirs(FSDirMkdirOp.java:61)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:3101)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:1123)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:696)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
build 的第 3 步 Extract Fact Table Distinct Columns 报错
后来新建了一个任务,竟然就好了~
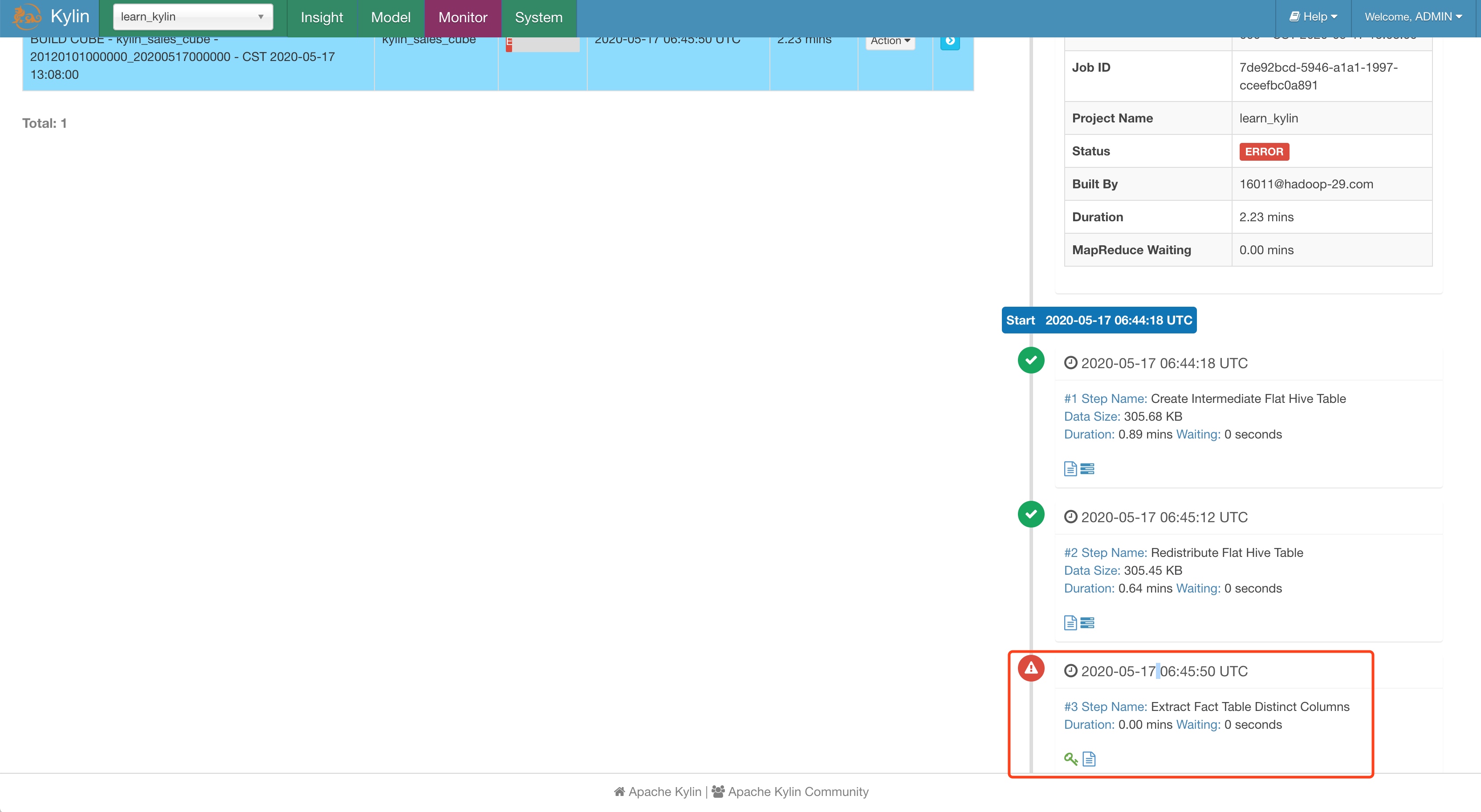
java.lang.IllegalStateException
at org.apache.kylin.engine.mr.steps.FactDistinctColumnsJob.run(FactDistinctColumnsJob.java:92)
at org.apache.kylin.engine.mr.common.MapReduceExecutable.doWork(MapReduceExecutable.java:144)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:179)
at org.apache.kylin.job.execution.DefaultChainedExecutable.doWork(DefaultChainedExecutable.java:71)
at org.apache.kylin.job.execution.AbstractExecutable.execute(AbstractExecutable.java:179)
at org.apache.kylin.job.impl.threadpool.DefaultScheduler$JobRunner.run(DefaultScheduler.java:114)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2
3
4
5
6
7
8
9
10
reference
- [1] 陈高英. 如何在 CDH 中部署及使用 Kylinopen in new window
- [2] 茂盛哥哥. kylin启动打不开 web UIopen in new window
- [3] 颠沛流漓. 基于CDH6.2kylin2.6.2安装部署open in new window
- [4] 赵安家. 021-cdh6.2+kylin2.6.2open in new window